Dataset Generation for Aerial Imaging and Object Detection
Dataset Generation:
Due to the absence of publicly available data sets with the markers at the target operational altitude (50-75 feet), a synthetic data set is needed to train our Object Detection model in conditions close to the competition.
Synthetic Database:
The synthetic dataset used in our object detection pipeline was procedurally generated using Blender’s 3D modelling suite. The goal was to simulate aerial views of markers placed at St. Mary’s County Regional Airport, closely mimicking the SUAS 2025 competition environment. To this end, we first constructed a 3D mock-up of the airport’s runway and its surrounding grass field using Blender’s mesh modelling tools. On this simulated runway, we placed 3D models of various SUAS target markers such as stop signs, mannequins, and vehicles. These models were sourced from publicly available online repositories like Sketchfab and TurboSquid.
A total of 90 images per class were rendered by systematically varying the virtual drone camera’s position and orientation. The camera was rotated about both its local and global axes to produce a diverse set of viewpoints. Additionally, lighting conditions were changed dynamically to simulate different times of day and weather scenarios. The rendering process was fully scripted using Blender’s Python API, which allowed us to batch generate over 1,300 images. Parametric control over camera angles and lighting was key to ensuring dataset diversity. The same Python scripts also extracted exact 2D bounding box annotations from the 3D scene, thus enabling accurate and fully automated labelling in YOLO format.

To enhance the detector’s generalization to real-world data, we incorporated a dataset of over 10,000 real images sourced from public datasets and in-house captures. Approximately 9,000 of these images came pre-annotated in YOLO format, while an additional 1,000 images were manually labeled using tools like MakeSense.ai and. To further improve the model’s robustness, we applied extensive image augmentations including random rotation, translation, shear, contrast changes, Gaussian blur, and exposure variations. This increased the total number of training samples to more than 25,000, significantly expanding the variety of poses, scales, and lighting conditions in the dataset.
Training Methodology:
Our training pipeline follows a three-stage curriculum learning strategy using a Faster R-CNN model with a ResNet-50 FPN backbone. In the first stage, the model is trained solely on the synthetic Blender dataset. This helps it learn geometric priors and object shapes from perfectly labelled, noise-free images. Training is conducted using the PyTorch detection framework, with the SGD optimizer and a StepLR scheduler. This setup ensures stable convergence while gradually reducing the learning rate over time.
After the synthetic-only training converges, we transition to a second stage where the model is trained on a mix of synthetic and real images. In this stage, we freeze the lower layers of the ResNet-50 backbone (conv1 through layer2), which are responsible for capturing general edge and texture features. The remaining layers, including layer3, layer4, the region proposal network, and the detection heads, are unfrozen and fine-tuned using a lower learning rate of 1e-4. This helps the model adapt its high-level features to the domain of real-world drone imagery while preserving the fundamental representations learned from synthetic data.
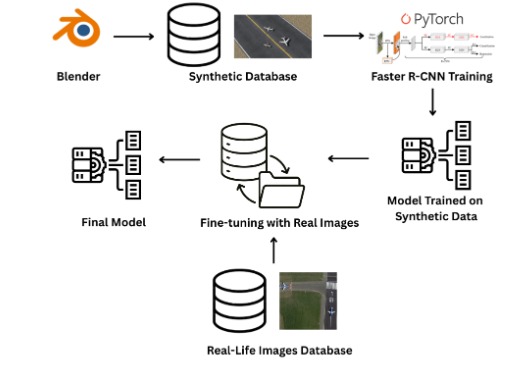
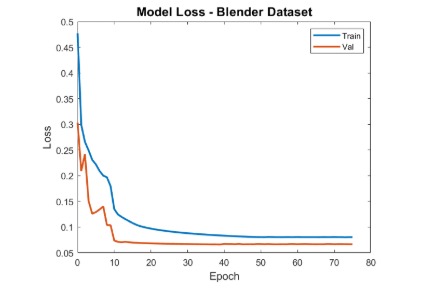
In the third and final stage, the model is fine-tuned predominantly on real images (90% real, 10% synthetic). At this point, all backbone layers are unfrozen. We further reduce the learning rate to 1e-5 and apply a MultiStepLR scheduler to fine-tune the model weights with high stability. This stage focuses on adapting the model to the full complexity of real-world textures, lighting, and occlusions captured by drones during flight.
